


Power of RAG and OpenAI’s Function-Calling for Question-Answering
Streamlining Q&A Process with RAG and OpenAI’s Latest function-calling method

This is a two-part article that discusses topics like using RAG for question-answering systems and using OpenAI’s latest function-calling method.
Retrieval Augmented Generation for Question-answering
If you’re tired of manually searching through documents or databases to find the information you need and want a more efficient way to extract data from external sources, you may be interested in using Retrieval Augmented Generation (RAG).
Retrieval-Augmented Generation (RAG) is a new approach to question-answering that combines the strengths of extractive and generative question-answering models. RAG models first use a retriever to identify a set of relevant documents from a knowledge base. Then, they use a generator to create a new answer that is based on the retrieved documents and the original question.
RAG retrieves data from outside the language model (non-parametric) and augments the prompts by adding the relevant retrieved data in context. — Amazon
To know more about RAG, you can read Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
RAG simplified | What is RAG
In RAG, the external data can come from anywhere, say a document repository, databases, or APIs.
The first step is to convert the documents as well as the user query in the format so they can be compared and a similarity search can be performed.
And to make the formats comparable for searching, a document collection (knowledge hub) and the user-submitted query are converted to numerical representation, called embeddings, using embedding language models.
The document embeddings are essentially numerical representations of concepts in the text, or we can say vectors. The embeddings can be stored in a vector database like Chroma, or Weaviate.
Next, based on the embedding created from the user query, the similar text is identified in the document collection by a similarity search in the embedding space.
Then the
prompt + entered_textis added to the context. The whole prompt is now sent to the LLM and because the context has relevant external data along with the original prompt, the model output is relevant and accurate.
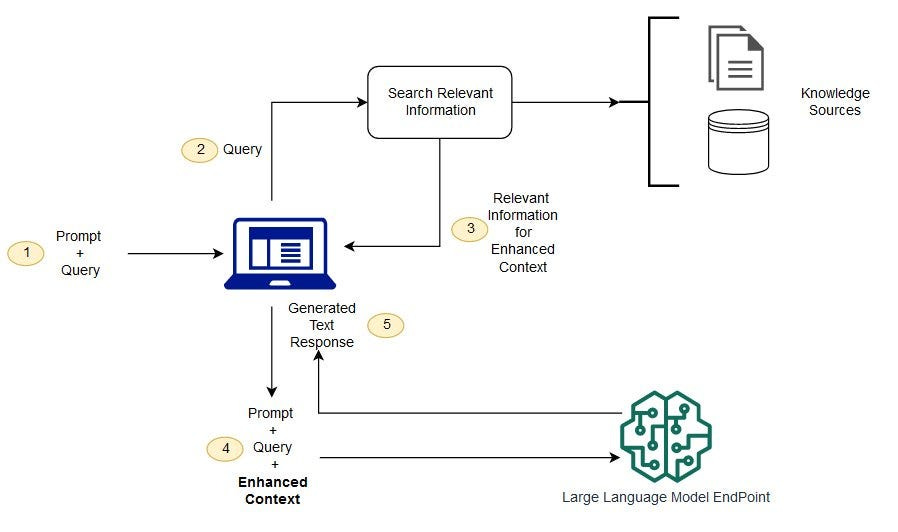
source: Amazon
Q&A application using OpenAI
Now that we have some idea about the RAG Q&A systems, we can begin experimenting and try building an application that leverages the RAG concepts we have discussed above. Let’s begin!
Text extraction
We start with extracting the data from the documents. Here we are going to use only PDF documents.
Some of the packages that can help to extract text from documents are —
PyPDF2
pdf2image
pytesseract
def extract_data_from_scanned_pdf(file_path: str) -> str:
data = ""
config = r'--oem 2 --psm 6'
images = convert_from_path(file_path)
for i in range(len(images)):
img = np.array(images[i])
data += pytesseract.image_to_string(img, config=config)
return dataBy leveraging the power of OCR technology and libraries like pytesseract and pdf2image, this function can help users automate the process of extracting text data from scanned documents.
Splitting text into smaller
The extracted data can be too big for the language model to ingest. So, the next step is to split the data into smaller chunks.
def get_data_chunks(data: str, chunk_size: int):
text_splitter = CharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=5, separator="\n", length_function=len)
chunks = text_splitter.split_text(data)
return chunksThis function can be useful for splitting a large string of text data into smaller and more manageable chunks using the “CharacterTextSplitter” object from Langchain and specifying the desired chunk size.
Creating the knowledge hub or database
We are done splitting the data into smaller chunks of text. Now we need to convert these chunks into embeddings and store them in a vector database. We can use Chroma or FAISS or any other database.
def create_knowledge_hub(chunks: list):
embeddings = OpenAIEmbeddings()
knowledge_hub = FAISS.from_texts(chunks, embeddings)
return knowledge_hubUsing a Q&A chain for information retrieval
Next, a large language model (LLM) is used to ask questions by retrieving the relevant answer from a given text data using a retrieval augmented generation (RAG) pipeline.
def get_answer_LLM(
question: str,
data: str,
chunk_size: int = 1000,
chain_type: str = 'stuff',
) -> str:
if data == "":
return ""
chunks = get_data_chunks(data, chunk_size=chunk_size) # create text chunks
knowledge_hub = create_knowledge_hub(chunks) # create knowledge hub
retriever = knowledge_hub.as_retriever(
search_type="similarity", search_kwargs={"k": 2}
)
chain = RetrievalQA.from_chain_type(
llm=OpenAI(temperature=0.3, model_name="text-davinci-003"),
chain_type=chain_type,
retriever=retriever,
return_source_documents=True,
)
result = chain({"query": question})
return result['result']
The
as_retrievermethod of the knowledge hub object is used to create a retriever object that can be used to search for similar text in the knowledge hub. The retriever object is configured to use a similarity search with a search parameter “k” of 2.The
RetrievalQA.from_chain_typemethod is used to create a retrieval augmented generation (RAG) pipeline. The function uses thechainmethod of the RAG pipeline to generate an answer to the input question.
Orienting all the above steps into a RAG pipeline for information retrieval and question answering from documents by using Streamlit and turning the notebook into an MVP application.

Question-answering application using Langchain with OpenAI
Information retrieval using OpenAI’s Function Calling feature
Traditionally, Q&A applications require users to enter their questions and wait for the back-end to retrieve the answers by searching for relevant data. However, this method can be time-consuming and inefficient, especially if you have a large number of questions to answer.
One alternative approach is to auto-answer some of the important questions from a template. This way, you can retrieve the necessary data with just a single click of a button. To achieve this, I’ve used OpenAI’s most recent update, function-calling, which is available for public use.
OpenAI Platform
Explore developer resources, tutorials, API docs, and dynamic examples to get the most out of OpenAI’s platform.
Some of the features that function-calling provides —
Create chat-bots that answer questions by calling external tools (e.g., like ChatGPT Plugins)
Convert natural language into API calls or database queries
Extract structured data from text
Answering some questions from documents.
Writing the function to generate the message and retrieve the arguments as a response from the function-calling method.
def message_generate(data:str) -> List[Dict[str, str]]:
prompt = f"Please extract information from this given data: {data}." # create the prompt
messages = [{"role": "user", "content": prompt}]
return messages
def function_call(
data: str,
functions:List[Dict[str, any]],
model:str ="gpt-3.5-turbo-0613",
function_call:str="auto"
) -> Dict:
arguments = {}
message = message_generate(data) # create the message
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k",
messages=message,
functions=functions,
function_call="auto"
)
arguments = eval(response.choices[0]["message"]["function_call"]["arguments"]) # convert to dic
return arguments
To use OpenAI’s function for automating your Q&A process, you’ll need to provide a message argument with the role and content (prompt) field as input. The prompt is what directs the model with the tasks to be done and determines the type of information that will be retrieved.
When using OpenAI’s function, it’s important to ensure that you provide the necessary arguments in the correct format. The required fields can be found in the function’s documentation, which provides detailed instructions on how to use the function effectively.
Define the function/properties needed
Now, we need to format the functions or the fields to be extracted. Naming, them as functions.
functions = [
{
"name": "get_answers",
"description": "Get the answers of the questions asked",
"parameters": {
"type": "object",
"properties": {
"What is the date of the lease?": {
"type": "string",
"description": "Date of the lease document",
},
"What is the length of the tenancy?":{
"type": "string",
"description": "The length of the tenancy"
},
"What is the address of the property being leased?":{
"type": "string",
"description": "The adress of the property that is being leased"
},
},
"required": [
"What is the date of the lease?",
"What is the length of the tenancy?",
"What is the address of the property being leased?",
],
}
}
]It is a list of functions in JSON format that can be used to retrieve answers to specific questions asked in a document. The function is named “get_answers” and has a description that explains its purpose, which is to get the answers to the questions asked.
The function has a parameter object with three properties, each corresponding to a specific question.
Each question has a type of string and a description that provides additional context about the question being asked. The “required” property specifies that all three questions must be answered to retrieve the necessary information.
Appending the function-calling feature to our previous streamlit application and making it more robust and feature-rich, the application now take pdfs as input and generates answers by both RAG and the function-calling method.

OpenAI’s function-calling feature
Conclusion
OpenAI’s Retrieval Augmented Generation (RAG) method and the latest function-calling technique have revolutionized the way we approach data extraction, information retrieval, and answer generation. These techniques offer a more efficient and accurate way to extract and analyze large amounts of data, particularly in the context of question-answering systems.
By leveraging the power of OpenAI’s language models and vector databases like Chroma and FAISS, we can create knowledge hubs and RAG pipelines that automate the process of extracting relevant information from large datasets and generating accurate answers to complex questions. With the continued development of these technologies, we can expect to see even more exciting advances in the field of data analysis and information retrieval in the future.